Requirements:
- It should be able to scale millions of requests
- Able to support time series aggregation and fast ingestion
Architecture Overview
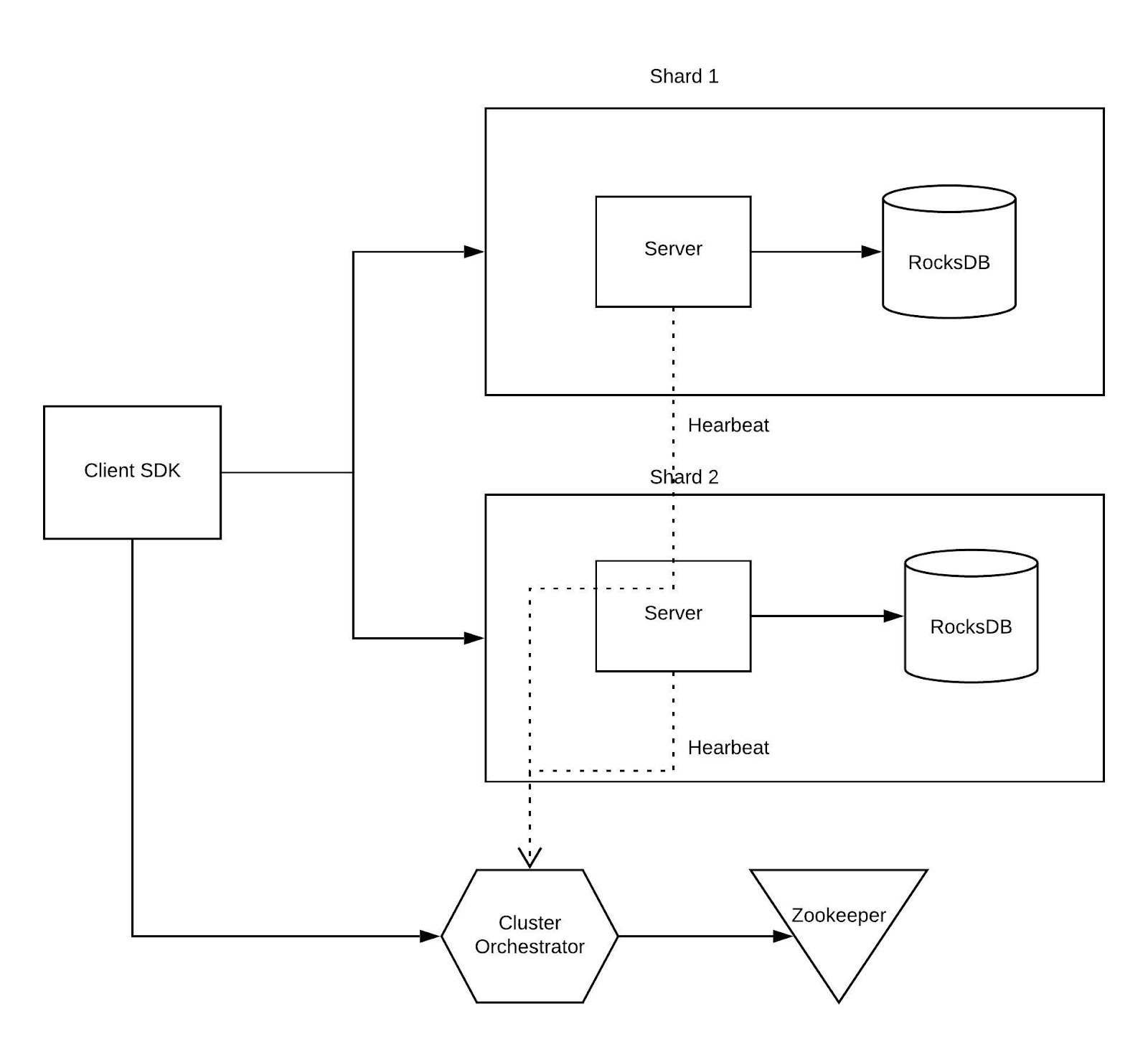
Design Tenets
- The timestamp needs to be converted from the ISO format to the unix time format.
- Primary key for database would be timestamp (which is in unix time format) and LSM tree would be used to persist the data. LSM trees are favourable for the high write systems
- The feature name would be appended to the time stamp.
- This key and value is stored as columnar storage on that machine.
- Split the data into different features and insert with multiple keys
- On the runtime, query the LSM and by creating the start key with the feature name and current time. Same we can do for the end key. The client need to do the partition the query based on the date and query the multiple shards
API for Time Series Database
Put (time, key, value)
- Time is unix timestamp
Get (start time, end time, key, aggregate by(time period) ):
Alternate Design
Cassandra as a time series database:
Cassandra is wide column store which can be used to store the time series database. It can be interpreted as two dimensional key value store. It is column family but not column oriented. Cassandra uses LSM structure to facilitate the high write throughput. It has two keys – partitioning key and cluster key.
Pros:
- High write throughput is suitable for the case of time series data
Cons:
- Time based aggregation is not supported in CQL or Cassandra
- Extra read of the data since it needs to read to read the complete value to fetch the value
- Need to add the time bucketing to bucketing the time data or need to add the data in one partition (which can have maximum 2billion rows)
Any NoSql database with LSM underlying structure, is a good contender for using as a time series database.
Case Study : Timescaledb
Timescaldb is implemented as plugin atop of PostgresSql database. It partitions the data based on the time range into smaller tables. Inserts are most frequent operations in time series data as compared to Update in the traditional workloads. Partitioning into smaller tables, keeps the index (mostly built as B tree) of the table to be small, which can be completely loaded into the memory. The smaller tables are called chunks which has feature as the primary key. Since the data is clustered based on primary key, all the data would be stored in sequential manner on the disk.
TimescaleDB has two types of nodes:
- Access Node
- Data Node
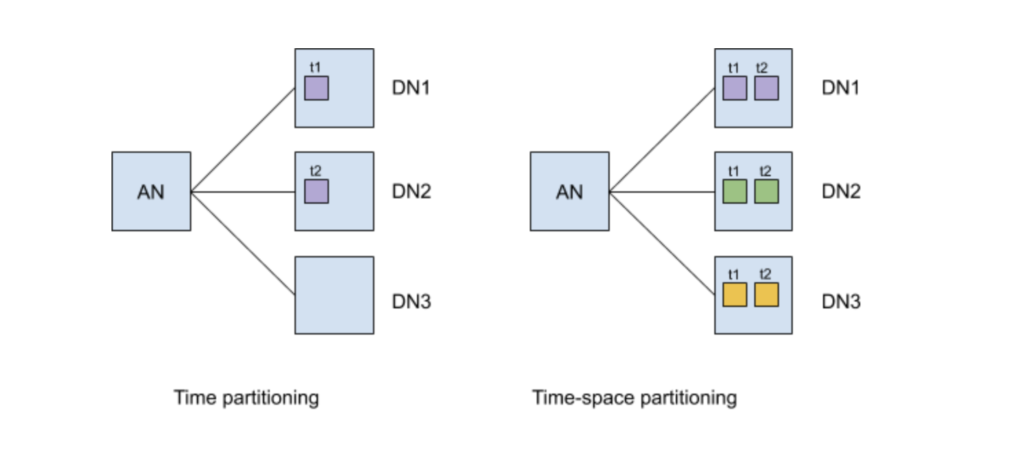
Access node contains the meta data about the chunks while the data nodes contains the data. TimescaleDB uses two phases commit to handle the failure scenario in case of inserts into multiple nodes. A chunk can reside only one node or it can be distributed on multiple nodes by specifying the space key (a key which is other than time). TimescaleDB creates a structure named as Hypertable to store the information about the chunks and schema. A user only interact with Hypertable, which internally store the data into the right chunk based on the time of the entry. This is little different from the traditional sharding since the data is first mapped to a chunk (based on the time-space partitioning) and then set to a node which has that chunk.
Code Highlights
TimescaleDB code is open source database and code can be easily cloned from Github. The code contains the following –
- hypertable.c
- Chunk Definition
- chunk.c