
A crawler service is responsible to fetch the different web pages recursively and persist their content. The crawled web pages can be used for ranking or extracting an information. Google bot is an example of web crawler and it concurrently run on thousands of machines to expedite the crawling of the web pages. The web crawlers generally follows the robots.txt file to determine which pages can be requested.
Thinking Process:
How to create multiple workers? Should we use microservices (since we need to be distributed crawler)
How to avoid the crawling of the same link
What database should we use for storing the visited links
Is there any API for the crawler
The trade-off between technologies to build the crawler – use we use Kafka or a queue (e.g. Rabbitmq)
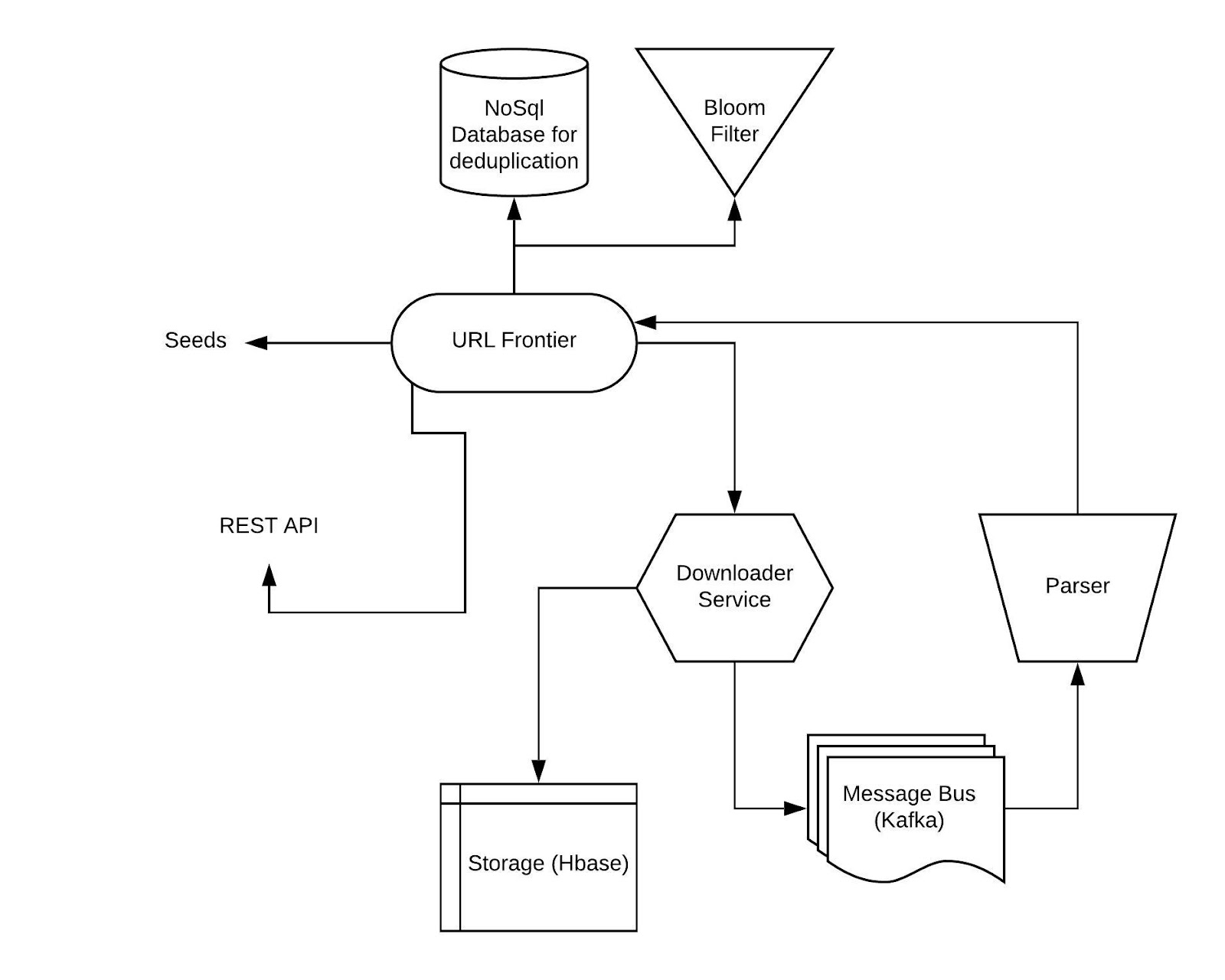
Architecture
Design Tenets
We would be having 3 microservices
1. Url Frontier service
2. Downloader service
3. Parser service
The REST API would be exposed to the client while gRPC would be used between the services.
URL Frontier Service
This service is seeded with the initial URLs and keep track of all the urls. It returns the url which needed to be crawled, based on the policies. It stores the urls in the database (which could be a ‘set’ data structure in redis) and the policies are read from a manifest file at time of the startup. Bloom filter are avoid the lookup in the database.
Downloader Service
Downloader service downloads the url and write the content of the pages to the message bus. It also persists the fetched response in Hbase. This service can be extended by adding the request and response middlewares. These middlewares can modify the request and response to the external servers.
Parser Service
Parse service parse the content of the response and after extract the hyperlinks from the response. After collecting all these hyperlinks, these are passed to URL frontier service.
API for the frontier service
We would be using the REST API with the following semantics to add the urls:
Method: POST
Parameters:
1. URL - the URL of the website
2. Deadline - Timestamp in Unix time
3. AuthID: authentication string for client/API key
4. Freshness: How fresh the crawl data should be (a number in days, default value: 1)
5. Partially: boolean (if it is fine to send the incomplete data to client if the timeline is about to pass, default value: True)
6. NotificationPreference: Mail/ Text Message/ API endpoint (If empty, default would be picked from the client preference)
Response:
Email/ Text message: Link to file on S3 with expiry
Data timestamp: When data was crawled
Data Complete: True/False
Callback API :
Method: POST
Parameters:
Location: s3 file location
TimeStamp: the date when data was crawled
DataCompleteness: True/False
In the failure case, there is no response to the client (if the deadline is passed).
Database and Schema:
Url Frontier
This service can use Redis – Set store the URLs which are already visited. Cassandra may not be a good choice since workload is a well balance of read and write requests.
Downloader Service
We have used the Hbase since it can utilize hdfs to scale across machines with the normal disks.
References
Open source implementation : Scrapy Design:




